Headscale Series:Build a Headscale Cluster That Scales to (Almost) Unlimited Devices
Audience: engineers, architects, and SREs already running headscale + Tailscale as a self-hosted control plane.
TL;DR: With clusterID sharding + shared Postgres + an admission/control service + query isolation + incremental netmap, you can evolve single-process headscale into a horizontally scalable clustered service—functionally close to Tailscale’s SaaS model.
1) Current State & Problems
In many real deployments (especially with default/monolithic setups), headscale shows these limits:
Single tailnet; weak tenant isolation
By default, there isn’t first-class multi-tenancy. Strong “tenant boundaries” (isolation, quotas, policies) are hard to achieve.Single-process design; hard to scale horizontally
As a monolith, headscale handles thousands of devices, but at tens of thousands the control-plane load (heartbeats, registration, policy changes, push fan-out) drives CPU/scheduling spikes.Netmap recomputed on every device/state change
Each device online/offline/heartbeat/ACL change triggers (near) full netmap recomputation. That O(N) cost at high event rates makes CPU the bottleneck.
These issues narrow the path to “SaaS-like headscale that serves 100k+ devices.”
2) Common Approaches: Pros & Cons
Approach A: One tenant = one headscale + one database
- Pros: excellent isolation; minimal code changes.
- Cons: massive resource waste; painful ops (N× upgrades/monitoring/alerts/certs/backups).
Approach B: Make upstream headscale truly multi-tailnet
- Pros: aligns with the goal.
- Cons: deep refactors across auth, data model, queries, caching, event bus, ACL interpreter, and netmap generator;
even with multi-tailnet, a single process remains a bottleneck.
3) Our Scalable Solution (Linear Growth)
Core idea: Turn headscale into a shardable worker node. Each node has a clusterID. All nodes share one Postgres (or a PG cluster), but each node only sees rows for its clusterID. In front, run an Admission/Control Service (ACS) that assigns tenants/users to a clusterID on first contact (sticky), enabling horizontal scale-out.
3.1 Architecture (ASCII)
1 | +-----------------------+ |
Key points
- Shared Postgres, but every read/write is filtered by cluster_id, which logically shards one big DB.
- ACS handles tenant creation, quotas, clusterID assignment, and first-time registration steering.
- Headscale nodes are “as stateless as possible”: durable state lives in PG; caches accelerate but are reproducible.
- DERP map, OIDC, ACLs, keys, etc. are stored per tenant / per cluster; queries are isolated.
4) Critical Implementation Details
4.1 Database Changes
4.1.1 Add cluster_id to all tenant/device tables
Add cluster_id to tables for tenants/users/devices/keys/routes/ACLs/sessions/netmap metadata and create composite indexes.
Example (conceptual):
1 | -- 1) Columns & defaults |
If you’re currently “one DB per headscale,” you can keep DB-level sharding for hard isolation—but shared PG + cluster_id gives better resource reuse and elasticity.
4.1.2 Enforce cluster_id in the data access layer
- On process start, resolve
CLUSTER_ID(env/flag). - Inject WHERE cluster_id = ? into every query via the ORM/DAO (e.g., GORM scoped query) or handwritten SQL.
- Guard against “unscoped” queries (fail fast).
Go sketch:
1 | type ClusterDB struct { |
4.2 Server-Side Changes
4.2.1 Process startup with clusterID
1 | # Each headscale node starts with its own cluster_id |
- Propagate
CLUSTER_IDto logs, metric labels, event topics, etc. - All internal logic operates only on this cluster’s data.
4.2.2 Incremental netmap + convergence
Problem: Full netmap recomputation is O(N); frequent triggers burn CPU.
Fix:
Graph decomposition: model netmap as “nodes + ACL edges + route prefixes,” so any change maps to a limited impact set.
Impact tracking: when device X / ACL Y changes, only recompute for the affected subset (same user/tag/route domain).
Cache + versioning:
- Maintain a netmap version per
(cluster_id, tenant/user). - Cache results in memory (LRU) or Redis with signatures.
- On push, only send when “subscriber_version < latest_version” (delta).
- Maintain a netmap version per
PG LISTEN/NOTIFY: triggers on change tables emit
NOTIFY netmap_dirty (cluster_id, scope_key). NodesLISTENand queue work with debounce (50–200 ms).
Sketch:
1 | type DirtyEvent struct { |
This is the CPU game-changer. In real clusters we’ve seen 60–90% average CPU reduction.
4.3 Admission/Control Service (ACS)
Responsibilities
- First-time admission and clusterID assignment (weighted by plan, geography, live load).
- Returns the target headscale URL and registration parameters (e.g., derived AuthKey, OIDC URL).
- Sticky placement: the same tenant/account consistently maps to the same cluster unless migrated.
Typical API
1 | POST /api/v1/bootstrap |
Placement algorithm: consistent hashing + load factors (CPU, session count, netmap backlog).
Rebalance: ACS maintains “migration plans”; new devices go to new clusters; existing devices migrate in batches (see 6.3).
5) End-to-End Flow (ASCII Sequence)
5.1 First-time device join
1 | Client -> ACS: POST /bootstrap (account, plan, region) |
5.2 Device change triggers incremental netmap
1 | Client(Device X) -> Headscale(A): heartbeat/route change |
6) Operations & Evolution
6.1 Deployment tips
PG/PG cluster: primary/replica with streaming replication; partition tables by
cluster_idor use partial indexes to handle hot tenants at high concurrency.Caching: local memory + optional Redis (share hot sets across instances; faster recovery).
TLS/DERP: one DERP map entry point; deploy multiple DERPs by region; all headscale nodes share the same DERP map.
Observability:
- Metrics:
netmap_rebuild_qps{cluster_id},netmap_rebuild_latency_ms{scope},notify_backlog,sql_qps{table},push_failures. - Logs: label by
cluster_idto isolate shard anomalies.
- Metrics:
6.2 Quotas & Productization
- Free tier: enforce “max devices per account” at ACS; deny extra registrations.
- Commercial: assign a dedicated clusterID (exclusive headscale node) per tenant to guarantee performance.
- Billing: track device online time and/or traffic (if you account for it) in PG; aggregate by clusterID + account.
6.3 Migration & Rebalancing (no downtime)
Add node C (clusterID=C); ACS routes new signups to C.
Gradual tenant migration:
- Mark tenant T’s “target cluster = C”;
- Issue hints so T’s devices switch to headscale(C) on the next reconnect;
- Devices naturally flip during heartbeat timeouts/reconnects;
- After confirmation, move T’s rows from A to C (same DB:
UPDATE ... SET cluster_id='C' WHERE tenant_id=T; cross-DB: ETL).
7) Code Drop (Samples)
7.1 Inject clusterID at startup
1 | func main() { |
7.2 Guard against unscoped queries
1 | // Every handler/usecase must use Server.scoped(), which enforces cluster_id |
7.3 LISTEN/NOTIFY for incremental work
1 | -- Change trigger |
8) Security & Isolation
- Tenant boundaries: dual filters—
cluster_id+tenant_id. Audit sensitive ops (ACL updates, key lifecycle). - Cross-tenant access: ACL interpreter forbids it by default; allow only via explicit “tenant-to-tenant allowlist.”
- Key material: encrypt at rest in PG (KMS/HSM). Headscale nodes do not persist secrets locally.
- Least privilege: ACS can only read/write tenant↔cluster mappings; no direct access to device sessions.
9) Aligning with a Tailscale-like SaaS
This design offers the SaaS core: multi-node control plane + shared state store + admission front-end.
- ACS orchestrates new tenant onboarding;
- Paid tiers map to different cluster strategies (shared vs. dedicated);
- Failure domains and capacity scale by node;
- Centralized monitoring, billing, and compliance.
10) Closing Thoughts
Turning headscale into a sharded cluster isn’t just “add more boxes.” The keys are:
- Keep the data plane simple, make the control plane incremental;
- Each node owns its shard; Postgres is shared but logically isolated;
- The Admission/Control Service handles tenant orchestration and load placement;
- Incremental netmap pulls CPU out of the “full-rebuild hell.”
With this in place, both single-tenant and multi-tenant deployments can achieve near-linear scaling—SaaS-like in practice. If you’re modifying source and aiming for production, share your load curves and topology—especially netmap hit rates and CPU deltas. Those usually decide whether you can push toward six-figure device counts.
11) Demonstration
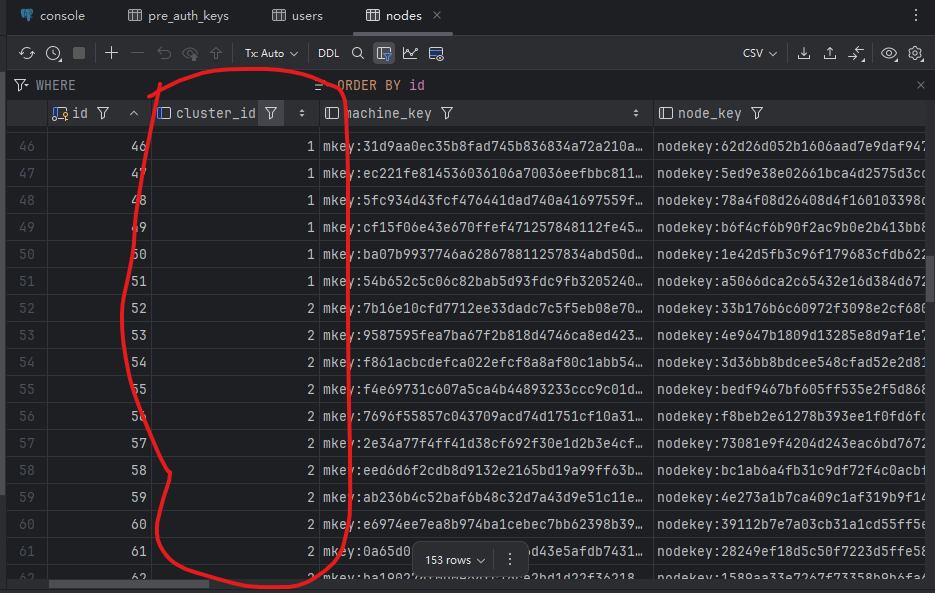
Deploy a two-node headscale using docker, create several users on each node, and then connect 50 clients. The two nodes share one PostgreSQL database.
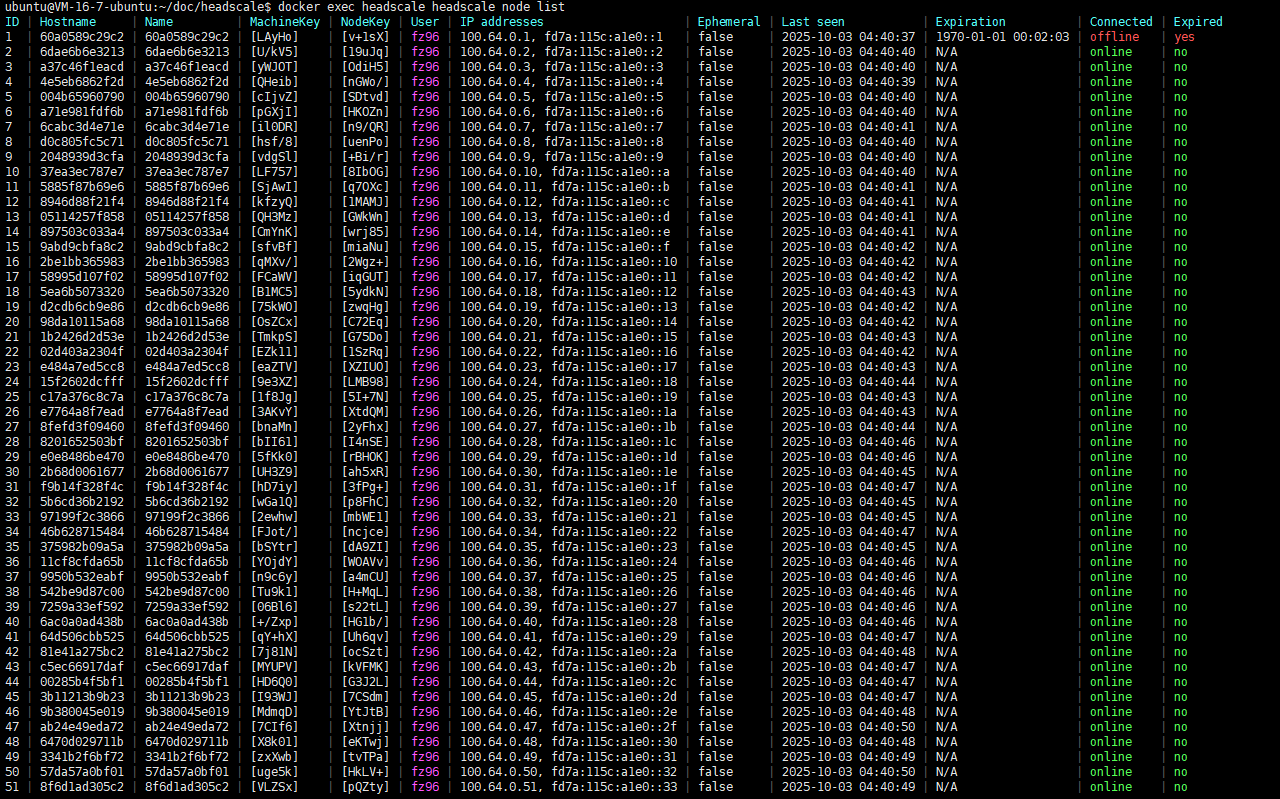
Node with cluster ID 1
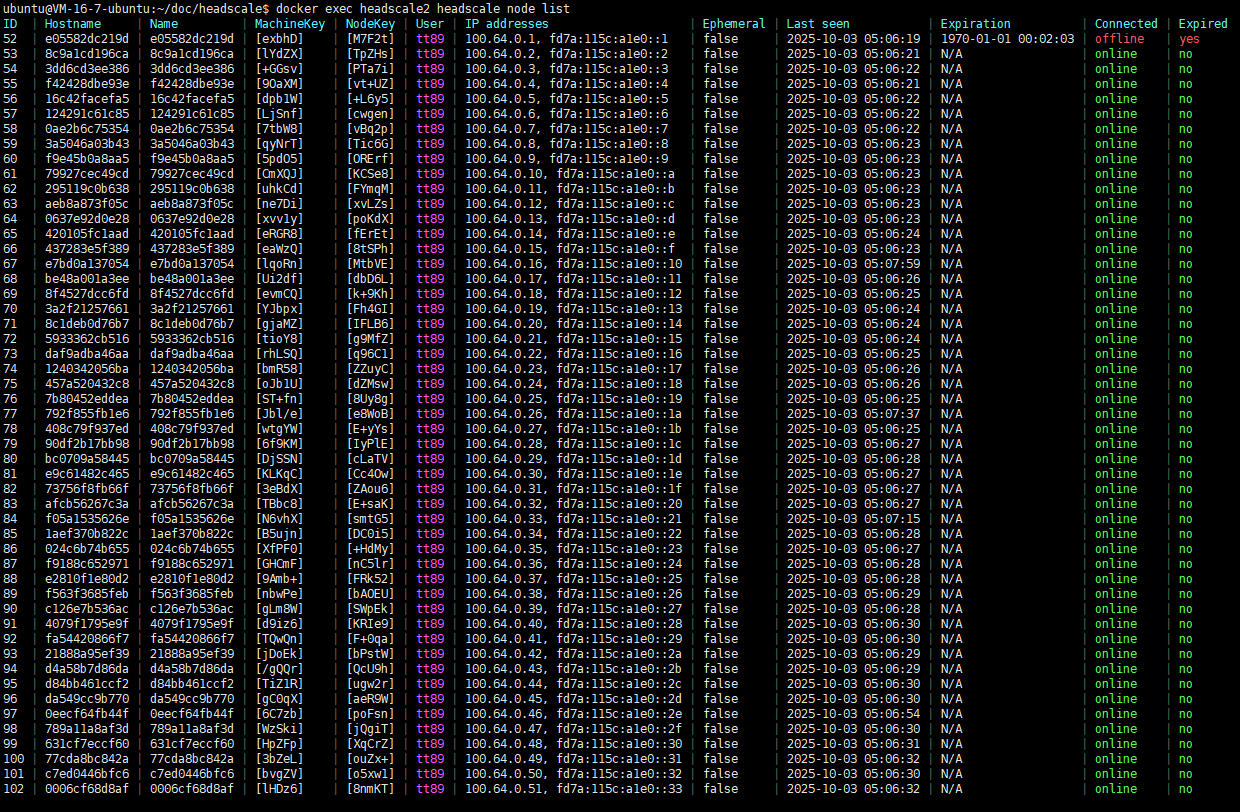
Node with cluster ID 2
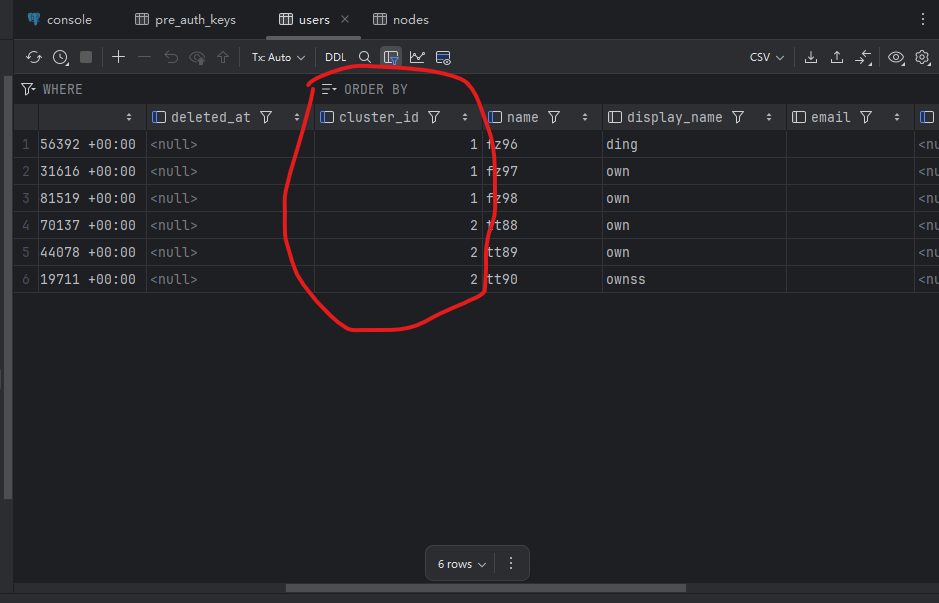
Database users table
Database nodes table
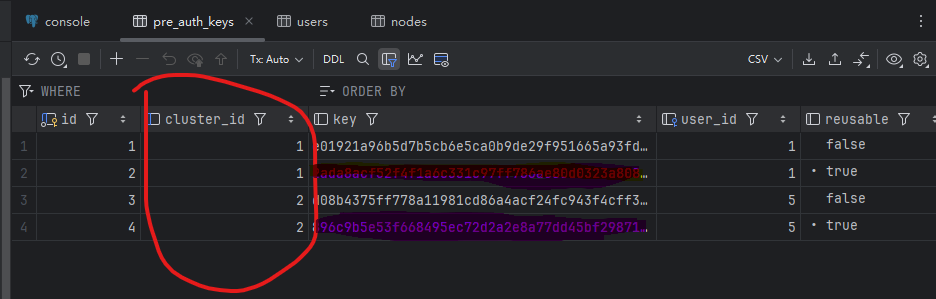
*Database pre-auth keys table