headscale 系列:组建 headscale 集群,把设备接入能力做成“无限接近无限”
目标读者:已经在用 headscale/headsacle + Tailscale 自建私有控制面的工程师、架构师与 SRE。
结论先讲:通过“clusterID 分片 + 共享 PG + 接入控制程序 + 查询隔离 + netmap 计算收敛”,可以把单体 headscale 改造成可线性扩展的集群化服务,形态上接近 Tailscale 的 SaaS。
1. 现状与问题
在不少实际部署(尤其是保守默认形态)里,headscale 暴露出以下限制:
单 tailnet 的租户隔离不足
默认形态下,租户隔离能力有限,难以做到天生的“多租户(multi-tenant)”边界和配额/策略独立。单机架构,横向扩展困难
headscale 作为单体进程,对上千设备尚可,上万设备时控制面心跳、注册、策略变更与推送的并发压力上来,CPU/调度抖动明显。每次设备状态变更触发 netmap 全量计算,CPU 开销大
设备上线/心跳/ACL 变更都会触发 netmap 计算,O(N) 的代价在高频事件下呈指数级放大,CPU 成为瓶颈。
这些问题使得“把 headscale 做成 SaaS、服务百万级设备”的道路变窄。
2. 常见改造路径的得失
做法 A:一个租户=一套 headscale + 一份数据库
- 优点:隔离极佳,改造量小。
- 缺点:极度浪费资源、运维爆炸(N 倍升级、监控、告警、证书、备份)。
做法 B:在原有 headscale 上直接做“多 tailnet”
- 优点:形态与目标一致。
- 难点:涉及鉴权、数据模型、查询、缓存、事件广播、ACL 解释器与 netmap 生成的全链路多租户化;
即使做成了多 tailnet,单体也仍旧是瓶颈。
3. 我们采用的方案概览(可线性扩展)
核心思路:把 headscale 变成“可分片的工作节点”,每个节点带一个clusterID,所有节点共享一个 PG/PG 集群,但每个节点只“看见”属于自己 clusterID 的数据。最前面放一个接入控制程序(Admission/Control Service),负责用户/租户到 clusterID 的分配与黏住(sticky),实现水平扩展。
3.1 架构图(文本版)
1 | +-----------------------+ |
要点
- PG 是共享的,但所有读写 SQL 都带 cluster_id 过滤,从逻辑上把一个大库切成多逻辑分片。
- ACS 负责:租户创建、配额/商业策略、clusterID 分配、设备首次注册引流。
- headscale 节点无状态化(尽量):持久状态都在 PG,缓存只做加速,可重建。
- DERP 映射、OIDC、ACL、Keys 等配置在租户维度/clusterID 维度落库,查询隔离。
4. 关键实现细节
4.1 数据库层改造
4.1.1 模型加 cluster_id
为所有与“租户/设备/密钥/路由/ACL/会话/netmap 元数据”相关的表新增 cluster_id 列,并建立联合索引。
示例(仅展示思路):
1 | -- 1) 字段与默认值 |
如果你目前是“一个库一个 headscale”,也可通过库级别分片进一步隔离,但共享 PG + cluster_id 能获得更好的资源复用与弹性。
4.1.2 访问层(DAO/ORM)强制带 cluster_id
- 在服务器启动时确定本节点的
CLUSTER_ID(来自环境变量或启动参数)。 - 在每一次查询前通过Context 中的 clusterID 自动注入到 SQL(如 GORM 的 Scoped Query、或手写
WHERE cluster_id = $1)。 - 没有 cluster_id 的查询直接拒绝(guard 断言),避免“漏过滤”。
示例(Go 伪代码):
1 | type ClusterDB struct { |
4.2 服务进程层改造
4.2.1 进程启动与 clusterID 注入
1 | # 每个 headscale 节点以不同的 cluster_id 启动 |
- 把
CLUSTER_ID注入到:日志前缀、指标 label、事件广播主题等。 - 所有内部逻辑只操作本 cluster 的对象集合。
4.2.2 netmap 计算的“增量化 + 粒度收敛”
问题本质:全量 netmap 计算是 O(N),高频触发会拖垮 CPU。
优化策略:
图模型分解:把 netmap 看成“节点集合 + ACL 边 + 路由前缀集合”的结果,任何变更落到有限的影响集合。
影响面追踪:当设备 X/ACL Y 变更时,只对受影响的节点子集重算(例如同一用户、同一 tag、同一 route 域)。
缓存 + 版本号:
- 为每个“(cluster_id, user/tailnet)”维护一个 netmap 版本号。
- 计算结果缓存到内存(LRU)或 Redis,带上哈希签名。
- 下行推送时仅在“订阅版本 < 最新版本”时增量下发。
PG 触发 LISTEN/NOTIFY:在变更表上触发
NOTIFY netmap_dirty (cluster_id, scope_key),节点LISTEN后队列化处理,限流 + 合并抖动(debounce 50–200ms)。
伪代码:
1 | type DirtyEvent struct { |
这一块是 CPU 成本收敛的关键,真实集群里能把平均 CPU打下来 60–90%。
4.3 接入控制程序(ACS)
职责
- 接入(首次注册)与clusterID 分配(可按租户权重、付费等级、地理延迟、节点负载)。
- 返回目标 headscale 节点地址与注册参数(例如可选衍生的 AuthKey、OIDC 跳转地址等)。
- 黏住(sticky):同一租户/账号始终返回同一 clusterID,除非运维执行迁移。
典型接口
1 | POST /api/v1/bootstrap |
分配算法:一致性哈希 + 负载因子(CPU、会话数、netmap 队列长度)。
再平衡:通过 ACS 维护“迁移计划”,让新设备去新集群;已有设备按批次做平滑迁移(见 6.3)。
5. 端到端数据流与时序(文本时序图)
客户端使用 tailscale 源码自行编译 + 自行开发的 ipn 程序用来管理 tailscaled。
5.1 设备首次接入
1 | Client -> ACS: POST /bootstrap (account, plan, region) |
5.2 设备状态变更触发增量 netmap
1 | Client(Device X) -> Headscale(A): 心跳状态/路由变化 |
6. 运维与演进
6.1 部署建议
PG/PG 集群:建议启用主从 + 流复制,表按
cluster_id做分区或partial index,高并发下效果更优。缓存层:本地内存 + 可选 Redis(跨实例热数据共享;断点恢复更快)。
TLS/DERP:DERP Map 固定入口,后端按地域部署多个 DERP;各 headscale 共用同一 DERP Map。
可观测:
- 指标:
netmap_rebuild_qps{cluster_id},netmap_rebuild_latency_ms{scope},notify_backlog,sql_qps{table},push_failures. - 采样日志:按
cluster_id打标签,便于排查某分片异常。
- 指标:
6.2 配额与产品化
- 免费用户:ACS 层限制“每账户设备数 N”,超出则拒绝分配注册令牌。
- 商业用户:可分配“独享 clusterID(专用 headscale 节点)”,实现资源与性能承诺。
- 计费:PG 里记录设备在线时长、流量(如只做控制面也可不记),按 clusterID+账户聚合。
6.3 迁移与再平衡(不中断)
新增节点 C(clusterID=C),ACS 把新注册导入 C。
老用户逐步迁移:
- 标记租户 T 的“目标 cluster=C”;
- 为 T 的设备签发“下一次重连时使用 headscale(C)”的引导参数;
- 设备在心跳超时/重连时自然切换;
- 完成后把 T 的数据从 A 复制到 C(同库可直接
UPDATE ... SET cluster_id='C' WHERE tenant_id=T;跨库需 ETL)。
7. 代码落地片段(示例)
7.1 进程入口注入 clusterID
1 | func main() { |
7.2 强制查询隔离的 Guard
1 | // 每个 handler / usecase 都必须通过 Server.scoped() 拿到带 cluster_id 的句柄 |
7.3 LISTEN/NOTIFY 增量任务
1 | -- 变更触发 |
8. 安全与隔离
- 租户边界:
cluster_id+tenant_id双层筛;敏感操作(ACL 更新、预共享 Key 生命周期)记录审计日志。 - 跨租户访问:在 ACL 解释器层强制禁止跨租户匹配,除非显式开启“租户互访”白名单。
- 密钥材料:私钥/预授权 Key 加密落库(KMS/密钥托管),headscale 节点无本地落地。
- 最小权限:ACS 仅可读写“租户/映射”相关表,不直接触碰设备会话。
9 与 Tailscale SaaS 形态的对齐
本方案在形态上具备“控制面多节点 + 后端共享数据存储 + 前置接入控制”的 SaaS 基本盘:
- 新租户接入由 ACS 编排;
- 不同付费层级对应不同 clusterID 策略(共享/独享);
- 故障域与容量按节点维度扩展;
- 运维面做统一的监控、计费与合规模块。
10. 结语
把 headscale 改造成可分片的集群,不是“堆机器”那么简单,关键在于:
- 数据平面保持简单,控制面增量化;
- 每个节点只负责本分片,PG 做共享但逻辑隔离;
- 接入控制程序承担“租户编排”与“负载均衡”;
- 通过netmap 计算收敛把 CPU 从“全量重建地狱”中解放出来。
按本文方案落地后,单租户/多租户都能获得近似线性的扩展能力,体验与 SaaS 形态接近。在资源可控的前提下,我们就能把 headscale 带到“无限接近无限”的设备连接规模。
11. 演示
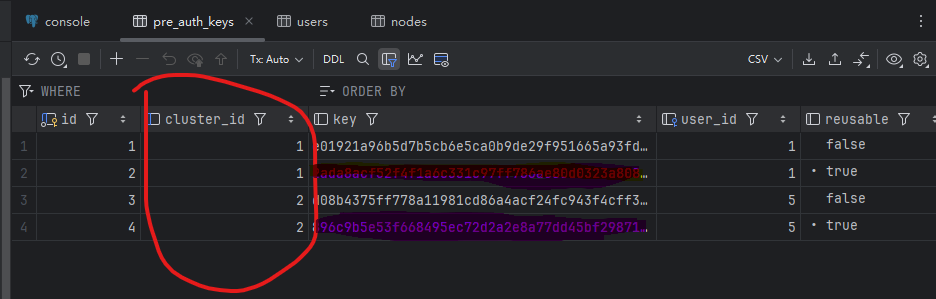
使用 docker 部署 两个节点的 headscale , 然后每个节点创建几个用户,再连接50个客户端。两个节点共享一个pgsql数据库。
cluster id 是1 的节点 node
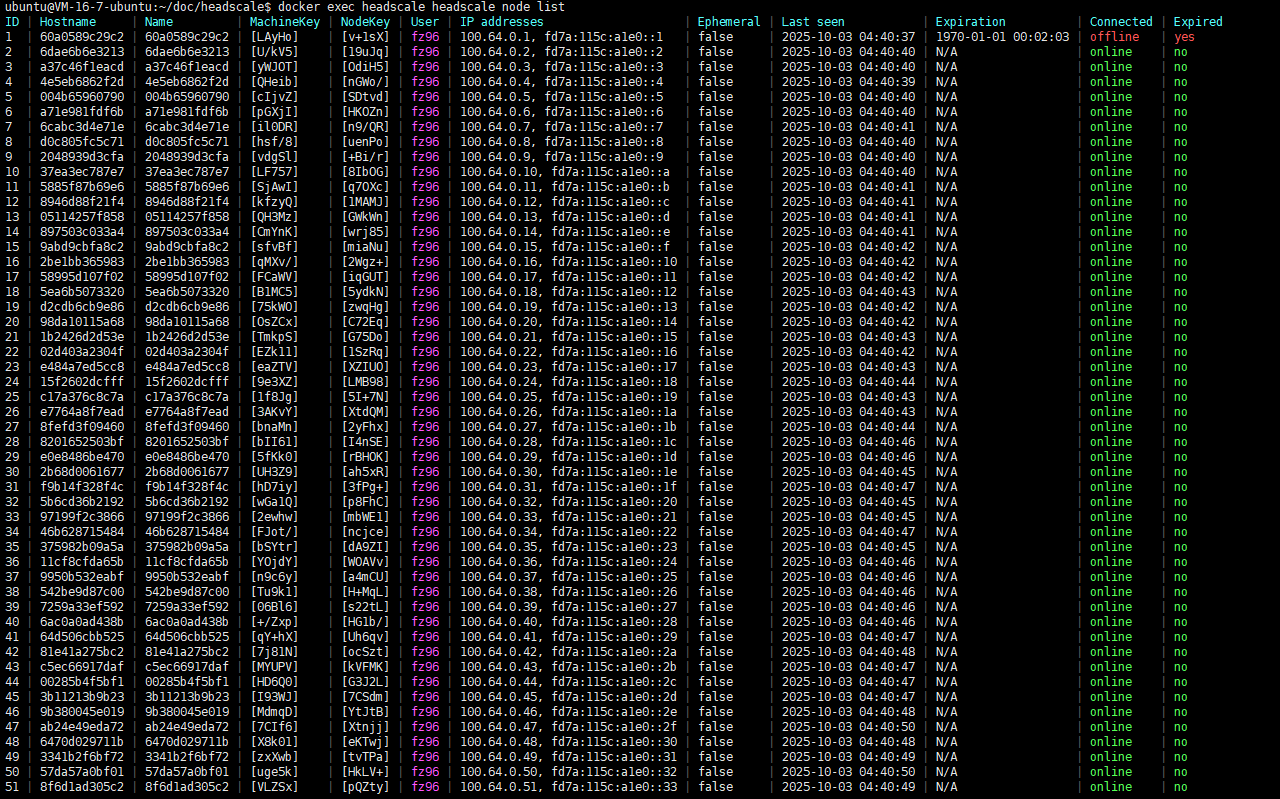
cluster id 是2 的节点 node
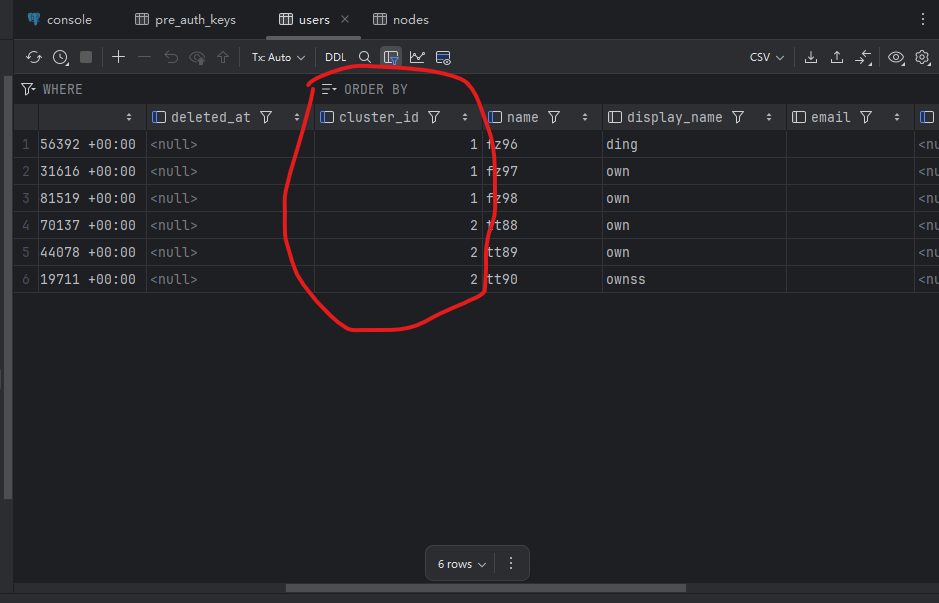
数据库 users 表
数据库 nodes 表
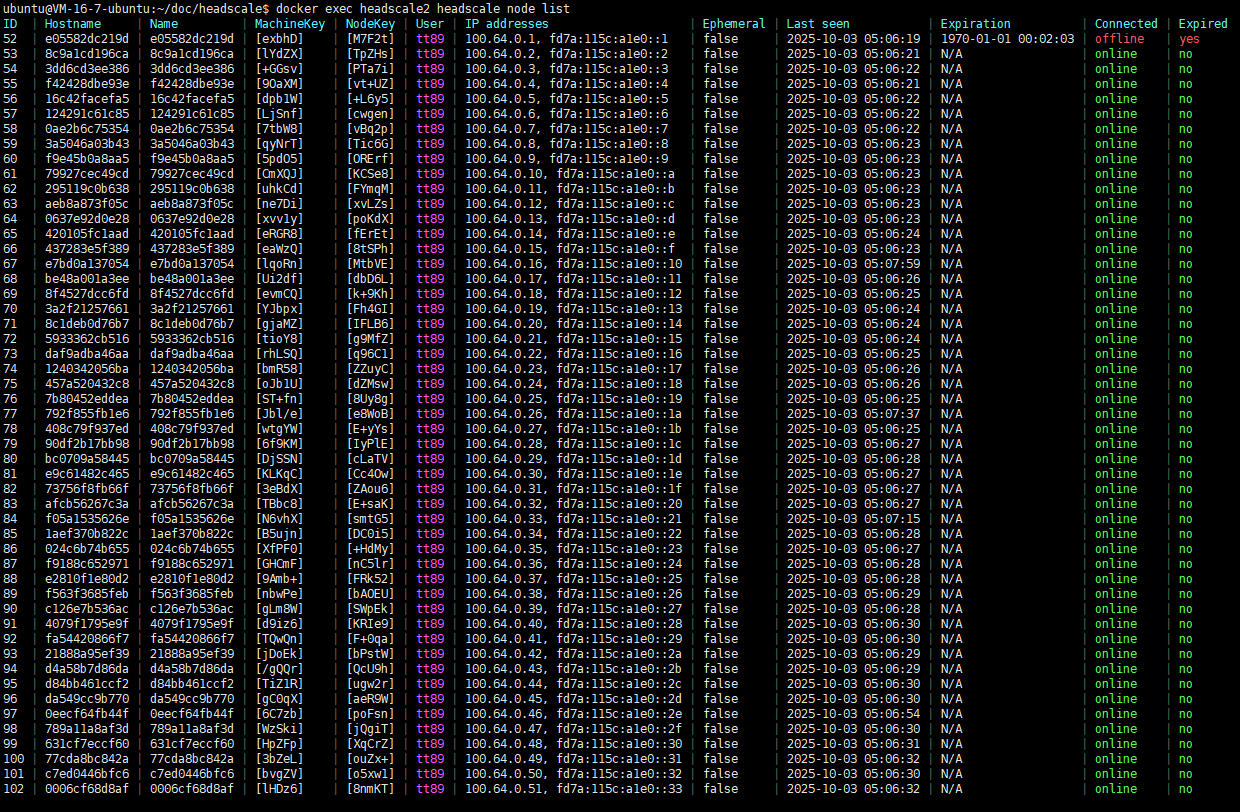
数据库 pre auth keys 表