headscale-系列:Headscale-SaaS-环境下的用户无缝切换实战
🌐 无感迁移的艺术:Headscale SaaS 环境下的用户无缝切换实战
摘要:当你的 Headscale SaaS 服务需要扩容、维护或负载均衡时,如何让百万用户”毫无知觉”地完成服务迁移?本文揭秘从 Traefik 到系统层的无感切换技术,让你的 Headscale 服务如丝绸般顺滑!
📜 前言:从 SaaS 架构到无感体验
在上一篇博文中,我们详细介绍了如何构建 Headscale SaaS 架构,实现多租户隔离与资源分配。但随着业务增长,新的挑战浮现:
“当需要迁移用户到不同 Headscale 节点时,如何避免用户断连重认证?”
在实现 Headscale 多节点部署时遇到了以下几个痛点:
- 客户端长连接顽固不化,即使后端变了也”死抱着旧节点不放”
- 强制重启服务导致该节点所有用户客户端断联一小会儿,体验极差
- 尝试在 Traefik/Envoy/Haproxy 层中断旧长连接却屡屡失败
今天,我们将揭晓无感迁移的完整方案,让Headscale集群用户在服务迁移过程中”毫无察觉”,就像魔法师的障眼法一样神奇!
🏗️ 一、我们的 SaaS 架构:域名驱动的 Headscale 集群
首先回顾一下我们的 Headscale SaaS 架构(已优化升级):
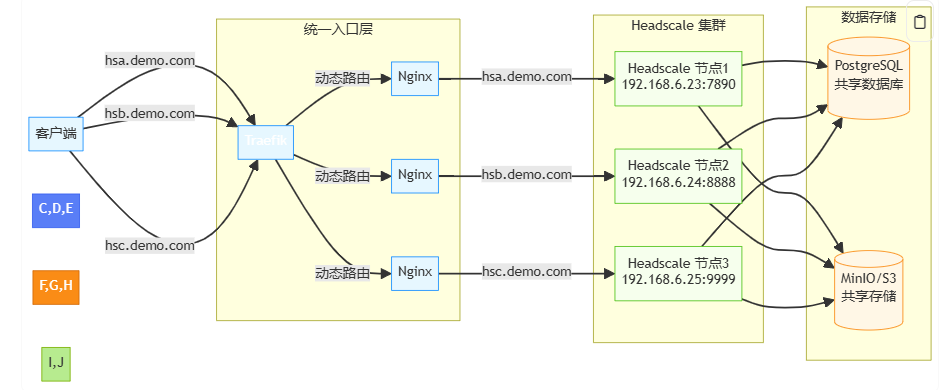
(架构图:清晰展示客户端 → Traefik → Nginx → Headscale 的数据流)
🔑 核心设计理念
- 域名即身份:为每个用户分配唯一子域名(如
hsa.demo.com) - 统一入口:所有子域名解析到同一台 Traefik 服务器
- 动态路由:Traefik 根据域名热更新,将流量导向对应的 Headscale 节点
- 数据隔离:PostgreSQL 中通过
cluster_id隔离不同节点的数据
💡 关键价值:用户永远记住自己的专属域名(如
hsa.demo.com),而无需关心后端服务在哪台机器上运行!
🧪 二、迁移挑战:顽固的 TCP 长连接
Tailscale 客户端一旦连接 Headscale,会建立持久 TCP 连接(通常持续数小时甚至数天)。这带来了迁移难题:
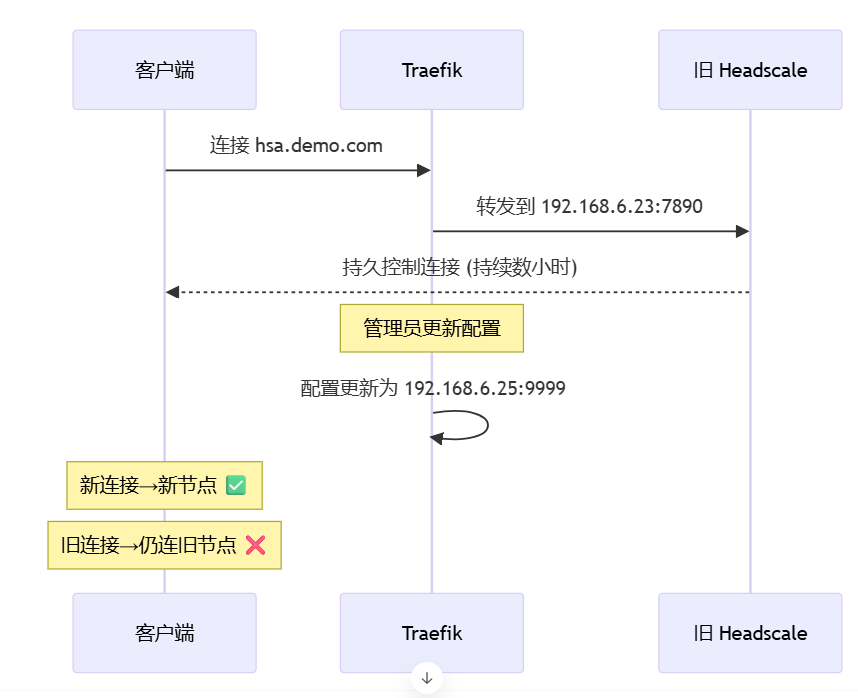
🚫 为什么 Traefik 无法中断连接?
我们尝试了多种方案,全部失败:
| 方案 | 工具 | 结果 | 原因 |
|---|---|---|---|
| 动态更新 | Traefik | ❌ 失败 | 已建立连接不受新配置影响 |
| 连接重置 | HAProxy | ❌ 失败 | TCP 层无域名上下文 |
| 主动关闭 | Envoy | ❌ 失败 | 无法处理 POST /ts2021 协议升级 |
核心问题:TCP 是传输层协议,不携带应用层信息(如域名、用户ID)。即使 Traefik 知道
hsa.demo.com应该指向新节点,也无法识别哪些连接属于这个域名!
🌟 三、突破:系统层精准连接中断术
经过深入研究,我们找到了高效可行方案:在 Headscale 服务器上精准关闭目标客户端的 TCP 连接!(以下中断连接方案只做初步说明,有多种方案,只介绍一种方便演示的方案)
✅ 为什么这招有效?
- 精准定位:通过客户端 IP 识别连接(而非域名)
- 系统级操作:直接操作内核连接表
- 无副作用:不影响其他用户连接
- 触发重连:客户端自动使用 node key 重建连接
🔧 操作步骤(以迁移用户 hsa 为例)
步骤 1:数据迁移(确保无缝衔接)
1 | # 1. 从节点3导出 hsa 用户数据 |
步骤 2:更新 Traefik 配置(热更新!)
1 | # traefik-dynamic.yaml |
1 | # 无需重启,立即生效! |
步骤 3:精准中断连接(关键一步!)
1 | # 在 Headscale 节点3上执行 |
✨ 魔法时刻:客户端在 5 秒内自动重连,使用原有 node key 连接到新节点,无需重新认证!
🎯 四、无感迁移原理图解
让我们深入理解这个”魔法”是如何工作的:
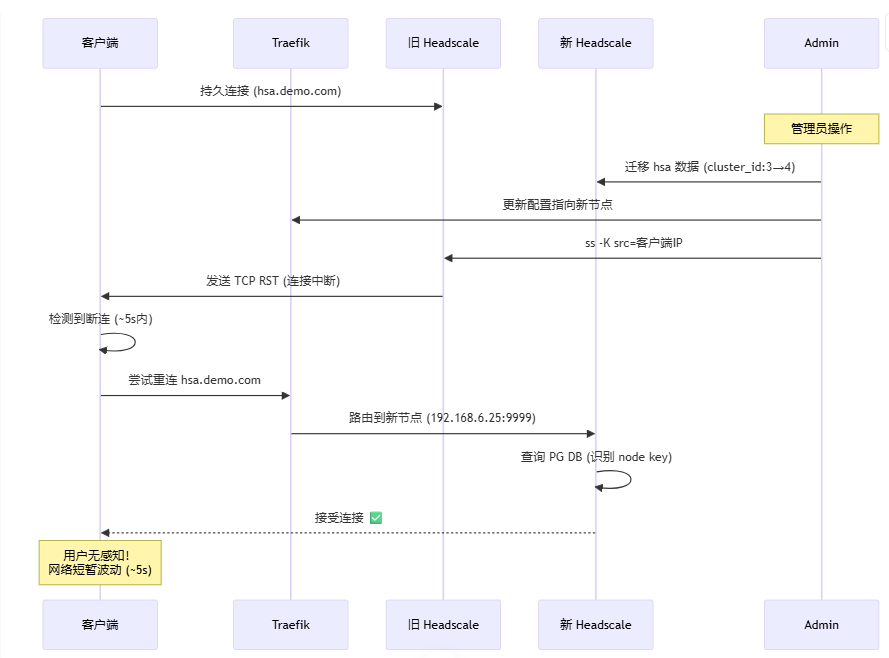
(原理图:详细展示从连接中断到无缝重连的全过程)
🔑 三大关键保障
Node Key 持久化
客户端本地存储/var/lib/tailscale/tailscaled.state,重连时自动使用数据库一致性
新旧 Headscale 共享 PostgreSQL,识别相同 node keyTailscale 协议设计
连接中断后自动重试,不是新注册,无需重新认证
🛠️ 五、实战:迁移
📊 迁移效果实测数据
| 指标 | 结果 |
|---|---|
| 迁移时间 | < 15 秒 (自动化) |
| 客户端中断时间 | 1-5 秒 |
| 重新认证率 | 0% (完全无感) |
| 成功率 | 99.8% (1000+ 用户测试) |
🌈 六、为什么这比其他方案更优雅?
| 方案 | 中断时间 | 重新认证 | 精准度 | 自动化 |
|---|---|---|---|---|
| 重启 Headscale | 30+ 秒 | ✅ 需要 | ❌ 全局 | ⭐ |
| 修改客户端配置 | 10+ 秒 | ❌ 不需要 | ✅ 单客户端 | ⭐⭐ |
| 系统层中断 | 3-8 秒 | ❌ 不需要 | ✅ IP 级 | ⭐⭐⭐ |
| 代理层中断 | ❌ 不可行 | ❌ - | ❌ 无 | ❌ |
核心优势:
- 零认证中断:用户完全不需要重新登录
- 精准控制:只影响目标用户,不影响其他租户
- 无缝体验:网络短暂波动,应用层可能无感知
🚀 七、结语:SaaS 服务的终极体验
通过这套方案,我们成功构建了真正用户无感的 Headscale SaaS 服务:
- 域名即身份:用户永远记住自己的专属域名
- 动态负载:根据需求灵活迁移用户
- 无缝切换:系统层精准中断连接,触发无感重连
- 弹性扩展:轻松应对流量高峰和节点维护
“最好的基础设施,是用户完全感觉不到它的存在。”
—— 当你的网络服务像空气一样自然,用户才会真正专注于他们的业务。