headscale-tailscale在hard nat环境下使用UPnP的问题
问题
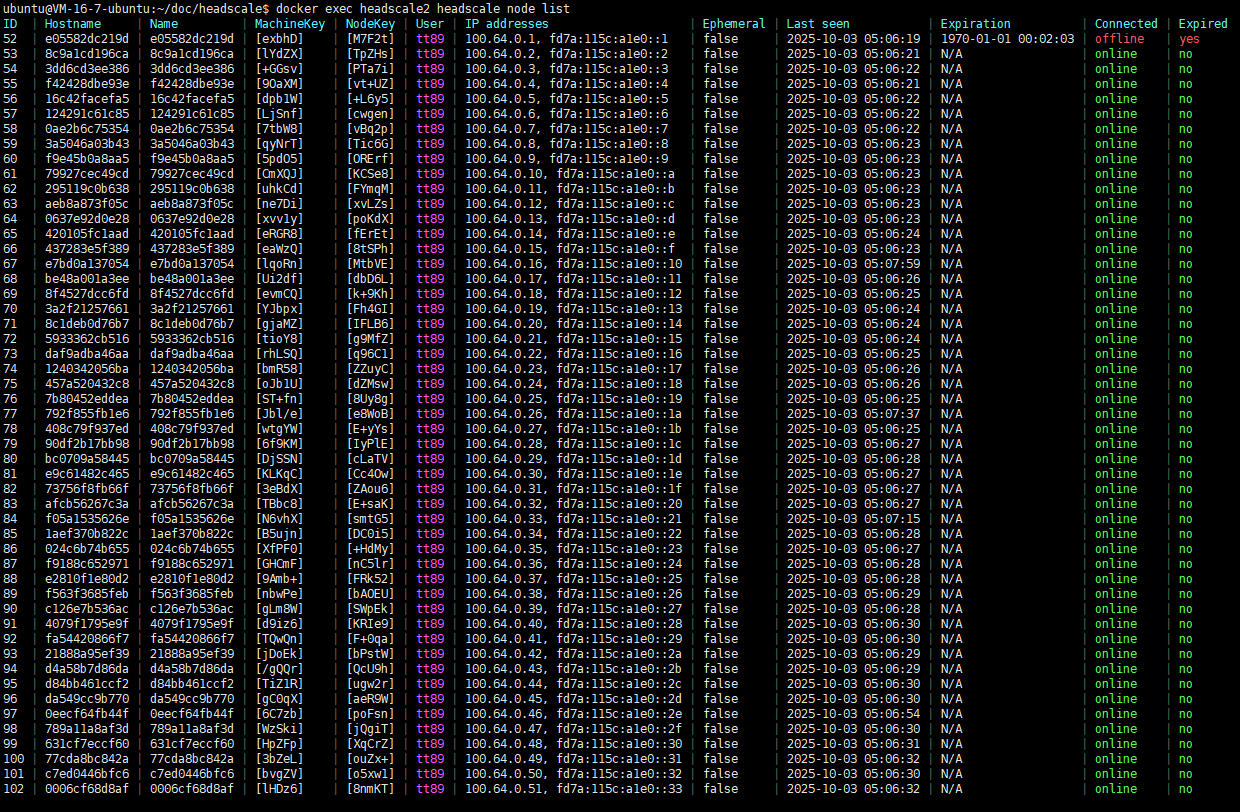
自建的headscale服务,在3台设备上登入同一个账号。这三台设备有2台是 windows电脑,记作A、B,1台是 Linux边缘网关记作C。三台都登入后,在ACL设置规则让3台设备互通,但是发现一个问题,即A、B可以相互 ping 通,A、B任何一台都无法 ping 通 C。只有当ssh到C设备,在C设备发起 ping A或B 后(可以 ping 通A、B),同时 A、B就能 ping 通 C了。
在 C 上使用 tailscale netcheck 命令发现如下信息:
1 | * UDP: true |
先说结论:
这个现象本质上是 C 在一个“比较难搞的 NAT + UPnP 环境”里,在它主动往外发一次包之前,Tailscale 没有为它准备好一个“可从公网直接打进来的端口映射”,所以 A/B 先打它时没路可走;等 C 主动 ping 一下 A 之后,通过 UPnP 成功在路由器上开了一个外部 UDP 端口,从那一刻起其它节点就能主动连到 C 了,所以你看到“C 先发一次之后就都通了”的效果。
1. 先解读一下 netcheck 的两组输出
C(嵌入式网关)上的 netcheck
1 | * UDP: true |
关键点:
MappingVariesByDestIP: true
说明 C 后面的 NAT 是 hard NAT / symmetric NAT,也就是“对不同目的地址会用不同的 (IP, port) 映射”,属于比较难穿的那种 NAT。(tailscale.com)PortMapping: UPnP
说明 tailscaled 在 C 上 成功通过 UPnP 在你家路由器上申请了一个外部端口映射(本质上就是给 41641/UDP 开了个洞),借助这个端口映射,哪怕后面依然是 hard NAT,也有机会做到“外面主动打进来”。(tailscale.com)
官方文档的解释是:
MappingVariesByDestIP = true→ “这个设备在不同 DERP 上看到的外网 (IP,port) 不一样,基本就是 hard NAT,只靠 UDP 打洞很难搞,通常只能走 DERP 中继”。(tailscale.com)PortMapping = UPnP→ 设备通过 UPnP / NAT-PMP / PCP 之类协议可以在路由器上开端口,这会把它从“完全 hard NAT”拉回到“相对容易打洞的 NAT”,提高直连成功率。(tailscale.com)
A(Windows)上的 netcheck
1 | * UDP: true |
MappingVariesByDestIP: false→ A 所在网络是 easy NAT 或无 NAT,端口映射对不同目的地址是稳定的,属于很好穿的类型。(tailscale.com)PortMapping:为空 → 说明 A 侧路由器没有用 UPnP/PCP/NAT-PMP 做额外端口映射,但因为 NAT 本身是“easy”的,所以也不需要。(tailscale.com)
所以整体形势是:
- A / B:在一个 easy NAT / 普通家用 NAT 后面,比较好打洞。
- C:在一个 hard NAT + 支持 UPnP 的路由器 后面,理论上可以通过 UPnP 把它变成“可被外界直接访问”的节点,但前提是 UPnP 端口映射已经真正建立。
2. 为啥“一开始 A/B ping 不通 C,C 先 ping 一下 A 之后就都好了”?
结合 Tailscale 的连接流程,可以大致这样理解:(tailscale.com)
刚开始时的状态
C 刚上线,tailscaled 还没完全跑完所有探测 / 打洞 / UPnP 端口映射逻辑,或者 UPnP 端口映射还没建立好。
从 headscale 的角度,它知道 C 的存在,但 对 C 的“可达外网端点(external endpoint)”信息还不稳定。
这时候 A/B 看到 C 在线了,就开始往 C 的 100.x IP 发 ICMP ping:
OS 把 ICMP 包扔进 tailscale0;
tailscaled 尝试用当前掌握的 C 的 endpoint 建立 WireGuard 通道;
由于 C 这边 NAT 比较凶(MappingVariesByDestIP:true),再加上此时可能还没搞定 UPnP 端口映射/打洞,导致:
- 直连 UDP 打洞暂时失败;
- DERP 也还在尝试协商 / 或者路径不稳定;
结果就是:从 A/B 看起来就是 “ping 不通 C”。
C 主动 ping A 时发生了什么
当你在 C 上执行
ping 100.x.x.x(A)或tailscale ping A的那一刻,会触发一堆事情:C → headscale/DERP 方向会有新的 DISCO / STUN / netmap 相关流量:
- tailscaled 再次探测外网出口,更新自己的
(公网IP, 端口)组合; - 再次执行或刷新 UPnP 端口映射,在路由器上为 C 打开一个稳定端口(你 log 里那几行 UPnP reply 就是这个过程)。
- tailscaled 再次探测外网出口,更新自己的
headscale 收到 C 更新后的网络信息后,会把 最新的 endpoint/portmapping 信息 发给 A/B。
A/B 端的 tailscaled 收到更新后再试着连 C,此时:
- 要么能通过 C 的 UPnP 映射端口 直接打进来;
- 要么至少能可靠地通过 DERP 建立中继通路。
于是,你看到:
- C ping A 正常;
- 紧接着再 A ping C 也突然开始正常了。
为什么后面重启 C / 重启 A 之后依然能互通?
有两种常见情况都能解释你看到的“之后一直通”:
UPnP 映射在路由器里是持久的或长时间不失效
很多家用路由的 UPnP 映射要么:- 写进配置(重启客户端不丢),
- 要么有很长的超时时间(比如几个小时甚至更长);
只要路由器本身没重启、没有清表,这个外部端口 → C:41641的映射就一直在。
所以哪怕 C 重启、A 重新登录,新的 tailscaled 继续用这个端口,A/B 都能直接打进来。
即便 UPnP 映射后来过期,硬 NAT 的行为对「这个 DERP/这个 peer」变得稳定了
一旦 C 对某些 DERP / 目标发了足够多的流量,NAT 的分配策略趋于稳定,配合 Tailscale 的路径探测与缓存,后续的打洞就更容易成功。
再加上 headscale/clients 会把可用路径缓存一段时间,所以“通了以后一直通”是常见现象。
3. 那个 PortMapping: UPnP 到底意味着什么?
结合文档简单翻译下:(tailscale.com)
这行不是说“现在一定在用 UPnP 通信”,而是说:
“当前设备已经确认可以通过 UPnP/PCP/NAT-PMP 之类协议在网关上申请端口映射,并且已经申请到了。”
这对 C 这种
MappingVariesByDestIP: true的 hard NAT 场景非常关键:- 单纯靠 UDP 打洞很难;
- 但一旦能在路由器上开一个 固定外部端口,其它设备就可以一直往这个端口打,而不用和 NAT 的随机策略博弈。
所以你看到的流程,其实很像:
- C 启动时还没来得及把 UPnP 端口映射搞定,A/B 先打 → 不通。
- 你从 C ping 一下 A,顺便触发了端口映射创建/刷新。
- 从那一刻起,C 变成“背后有静态端口映射的节点”,其它节点就可以随时主动连它了。
4. 这是不是 Bug?需要怎么调优/验证?
从 Tailscale 官方的角度,这更像是 复杂 NAT 环境下的时序问题 + UPnP 行为,不算标准的“功能 Bug”,但确实有优化空间。
你可以做几组实验来印证上面的推断:
4.1 看看 A ↔ C 之间实际是直连还是走 DERP
在 A 上:
1 | tailscale status |
观察输出里有没有:
direct x.x.x.x:41641→ 直连relay "hw-sh"/via DERP(hw-shanghai)→ 走中继
文档里有样例:前几包经 DERP,再切换到 direct 是正常的握手过程。(tailscale.com)
4.2 复现一次“刚上线不通”的过程,再对比 log
下次你可以:
重启 C(或者断电再上电,让 tailscaled 完全冷启动)。
先不要从 C 发任何东西,只在 A 上:
1
tailscale ping --tsmp --verbose C
TSMP ping 会绕过 OS IP 栈,直接看 Tailscale 通道本身,
--verbose会打印路径信息。(tailscale.com)如果这时候仍然 ping 不通,再在 C 上执行一次:
1
tailscale ping --tsmp --verbose A
对比前后两次
tailscale ping输出,以及/var/log/tailscaled.log中的 NAT 路径变化。
你应该能看到类似:
- 先只有
via DERP(...),甚至前几次完全没 pong; - C ping A 之后,出现
via 123.123.123.123:41641的 direct 路径。
4.3 试试禁用 UPnP 看行为是否更一致
在你这个 TP-Link(TL-XDR6030 易展版)路由器里,把 UPnP 功能关掉,让 C 完全处在 hard NAT + 无端口映射的环境,然后看看现象变成什么样:
- 理论上,这时 C 往往只能通过 DERP 收发数据,
PortMapping:会为空,MappingVariesByDestIP: true依旧。(tailscale.com) - 正常情况下,即便只能走 DERP,也不应该出现“完全 ping 不通,直到对方先发一次”的情况——如果还出现,就更像是 headscale 侧或你自己的 tailscale fork 里有逻辑 bug,可以重点排查。
5. 小结一句话版
之所以必须先在 C 上向 A/B 发一次包,才会出现 A/B 能 ping 通 C,是因为 C 所在的网络是 hard NAT,Tailscale 需要在 C 主动发包时,借助 UPnP 在路由器上开一个稳定的外部 UDP 端口;在这个端口映射建立之前,A/B 主动打 C 找不到可用路径,一旦映射建立并被 headscale/客户端缓存之后,后续就可以随时主动连 C 了。